Two hundred source definitions. Forty-seven job pipelines. Five hundred and sixteen transformation models. And not a single bespoke DAG written for any of them.
That's the headline result of a data platform we built to ingest, transform, and distribute healthcare and commercial data at scale - all driven by YAML configuration rather than hand-written pipeline code. Here's the architecture behind it, and what we're proud of delivering.
The Core Idea: Configuration Over Code
The guiding principle behind this platform is simple: adding a new data source should mean writing a YAML file, not a new DAG.
Instead of writing logic per source, we built general-purpose DAG generators that read metadata and produce the right Airflow behavior dynamically. The YAML files are the source of truth. This single decision shaped everything else about the platform.
Architecture Overview
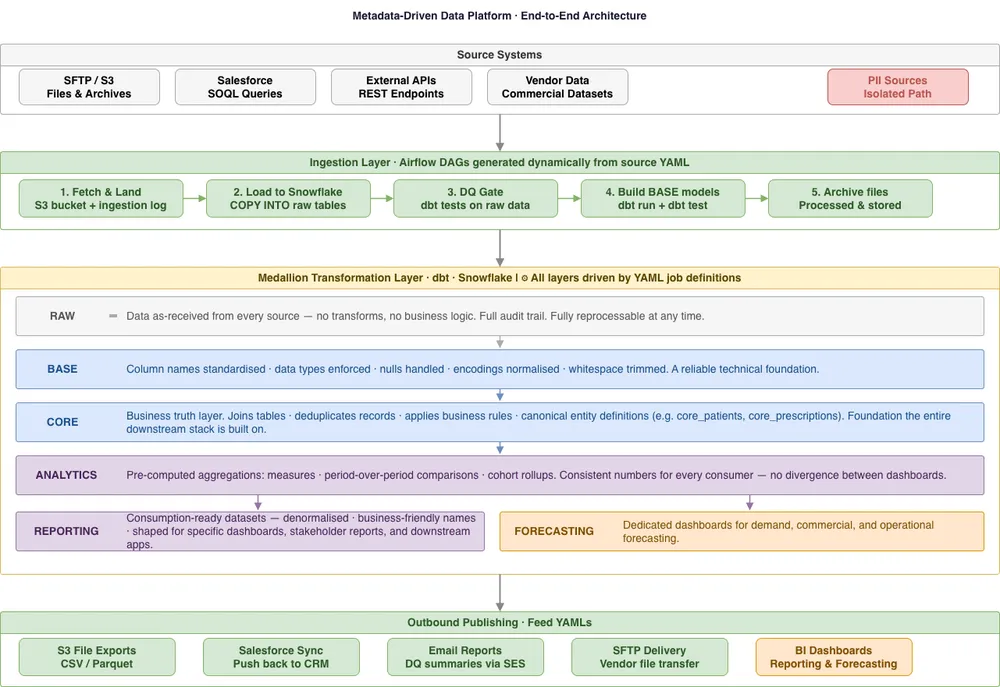
The platform has two connected repositories working in tandem: an orchestration layer built on Airflow, and a transformation layer built on dbt. Together they form a clean end-to-end pipeline - from raw vendor files to business-ready outputs distributed to downstream consumers.
The Ingestion Layer
For each data source, a YAML file defines everything the system needs to know: where the file comes from (SFTP, S3, Salesforce SOQL, or an external API), the filename pattern, load type, delimiter and encoding, archive behavior, and column-level data quality expectations.
A DAG generator reads these files at runtime and produces one Airflow DAG per source. Each DAG follows a consistent, reliable sequence:
- Fetch files from the source system
- Land them in an S3 input bucket
- Log ingestion status to a Postgres/RDS metadata store
- Load into Snowflake raw tables using COPY INTO
- Run dbt tests on raw data
- Build base models
- Run dbt tests again
- Archive processed files
Sensitive datasets follow a dedicated PII-specific path that routes them into an isolated Snowflake schema with separate bucket and stage configurations - keeping compliance requirements cleanly separated from the main pipeline with no extra work from the engineers adding new sources.
The Medallion Architecture: Six Layers of Trust
The heart of the transformation layer is a medallion-style architecture implemented in dbt. Rather than consolidating everything into a single schema and hoping for the best, we designed six distinct layers - each with a clear purpose, increasing levels of refinement, and explicit contracts between them.
The idea is straightforward: an engineer can look at any model path and instantly know how mature and trustworthy the data is. A raw_ prefix signals unprocessed ingestion straight from source. A reporting_ prefix signals a polished, validated, business-approved output. The layers in between are the journey from one to the other.
RAW is the landing zone. Data arrives here exactly as it came from the source - no transformations, no business logic. Every source table is preserved in its original form, giving a full audit trail and the ability to reprocess from scratch if needed.
BASE is where raw data gets its first treatment. Light cleaning happens here: standardising column names, enforcing data types, trimming whitespace, handling nulls, and normalising encodings. BASE models are thin but consistent - they create a reliable foundation for everything built on top.
CORE is where the real transformation happens. This layer joins tables, deduplicates records, applies business rules, and produces the canonical representation of each business entity. If BASE is about technical correctness, CORE is about business correctness. A model like core_patients or core_prescriptions reflects what those entities actually mean to the organisation - not just what arrived in a file. CORE is the truth layer the entire downstream stack is built on.
ANALYTICS builds on CORE to produce aggregated, metric-level models - pre-computed measures, period-over-period comparisons, cohort rollups. By materialising these in the warehouse rather than in BI tools, every consumer querying the data sees consistent numbers.
REPORTING packages analytics outputs into consumption-ready datasets shaped to the exact needs of specific consumers - dashboards, stakeholder reports, or downstream applications. These models are denormalised and labelled with business-friendly names, requiring minimal transformation by the end consumer.
FORECASTING is the specialised layer for predictive and modelling workflows. It draws from CORE and ANALYTICS to feed statistical models, demand forecasts, and scenario analyses - keeping predictive logic cleanly separated from the operational reporting stack.