Any Master Data Management (MDM) system that masters customer/vendor/partner data requires address standardization to be effective in matching addresses. Standardizing address terms and enriching the address with additional information is key to greater automated intelligent match and merge of customers and reducing data steward effort.
Any Master Data Management (MDM) system that masters customer/vendor/partner data requires address standardization to be effective in matching addresses. Standardizing address terms and enriching the address with additional information is key to greater automated intelligent match and merge of customers and reducing data steward effort.
Why do we need Address Standardization?
The need to address standardization stems from multiple issues. Address data from different data sources may have different structures. Some may contain only one street address line, while others may contain up to three. Textual address data may contain abbreviations like “Ave for Avenue or Rd for Road”. Sometimes non-standard street names like those named after individuals may be spelt differently in different sources. A landmark may be included in some address sources like “Near Quincy Market”. The specificity of the address also calls for standardization. An address may include the suite, room number and wing in one source whereas another source may only contain the street address. Since some sources have human-entered addresses, cities may be flipped for the borough or counties like “Queens” instead of “New York City”. More serious data issues include the zip code being specified wrongly or blank or one source specifying a 5-digit zip code vs the other specifying a 9-digit one.
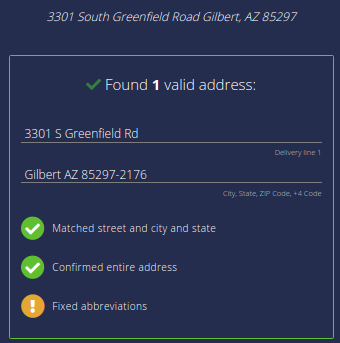
These variations in addresses make address matching a process that is already computation heavy due to the fuzzy matching nature more cumbersome. Many times the address standardization itself will reduce two raw addresses to the same standardized address, and an exact match is easily obtained. Without address standardization, the number of potential matches increases significantly since we have to relax the match thresholds to account for these variations. With the enrichment of addresses, the extra components can help develop more effective address-matching algorithms to improve match-merge efficiency.
How do we standardize addresses?
Multiple options are available to standardize addresses. Some are libraries like the python postal-address (https://github.com/scaleway/postal-address) library that uses rules and algorithms to standardize addresses. These libraries, however, have no idea about the real world and lack detailed information about a city or a state. They mostly address cleansing tools. You can read the documentation of postal-address here https://postal-address.readthedocs.io/en/develop/
In contrast, there are web services that offer APIs to standardize addresses. These web services actually provide better results because they’re geography aware and usually have some GIS backend source for verifying the validity of addresses. SmartyStreets (https://smartystreets.com/) is an official CASS-certified (CASS is a certification system from the USPS for address validation. Read more at https://smartystreets.com/articles/cass-processing). There are several benefits of using SmartyStreets for address standardization:-
- It parses the address and provides additional address components like “Primary Number”, “Street Name”, “Street Suffix”, etc., which can then be used in more advanced address matching algorithms.
- It corrects address errors like zip code mismatches, missing zip codes or other missing components.
- It provides various types of APIs which support single as well as bulk address standardization in python.
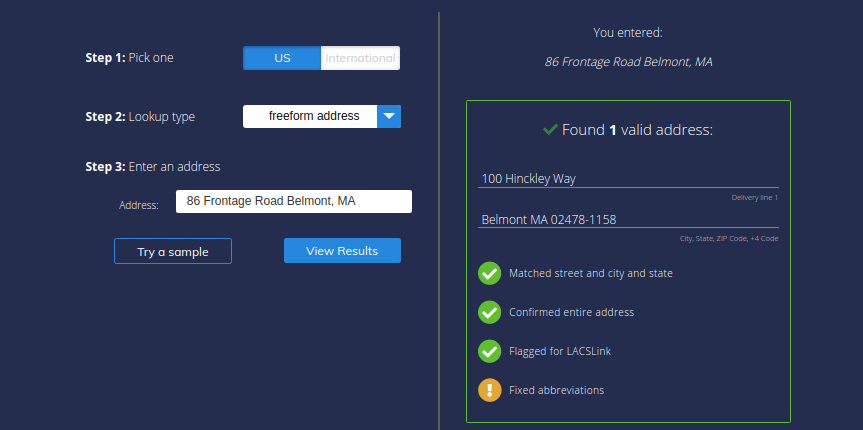
Address Parsed by Smarty Street
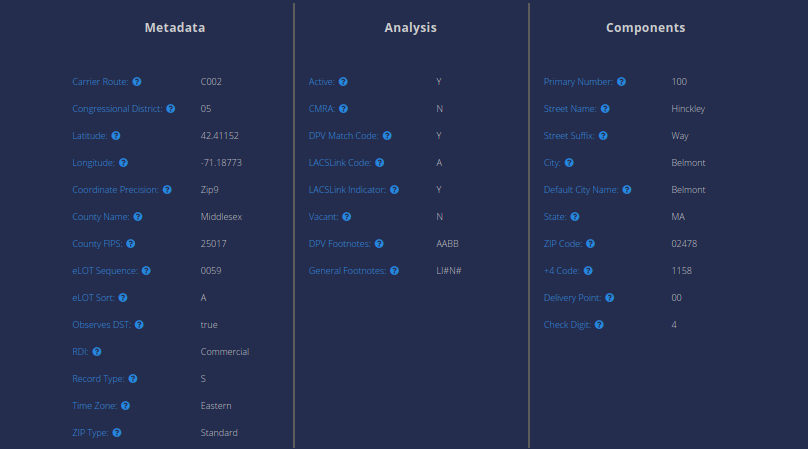
Additional Address component parsed by SmartyStreet
Conclusion
Most MDM systems performing customer match and merge require a standardization of the addresses for effective address matching and reduced data steward effort. Web APIs like SmartyStreets are highly recommended for the address standardization process since it provides error correction, additional address components, easy-to-consume APIs and even international address validations. Look to using an address standardization service in your next DWH/Data Lake process if you are rolling your own MDM system.
Incentius can help you set up an MDM system for your customer data and even a standalone address standardization process for other enterprise processes. Drop us a note at info@incentius.com